Dans ce TP, l’objectif sera de guider un robot vers une case cible dans un monde “en grille”. Nous implémenterons deux algorithmes: A* et Value Iteration
Ressources

Lisez les instructions ci-dessous
Prise en main
Ouvrez l’archive et exécutez le code à l’aide de python simulator.py. Par défaut, cette commande
vous montre simplement le monde généré.
Il est également possible de préciser une “seed” (graine), permettant de générer un autre monde. Par exemple,
si vous lancez python simulator.py -s 123, vous verrez un monde différent de celui par défaut (qui
utilise la graine 0).
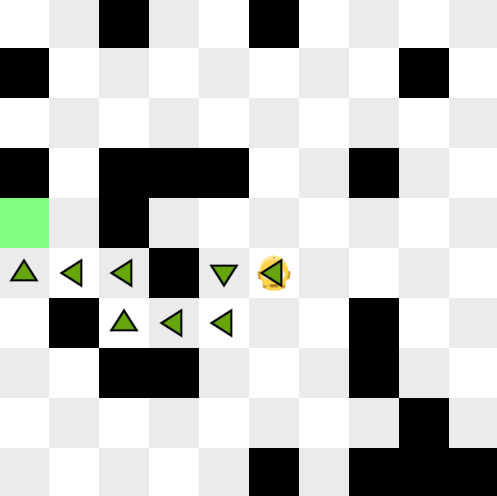
L’objectif est, lorsque c’est possible, de trouver le plus court chemin menant le robot à la position cible
(ici la case verte). Un exemple est montré si vous utilisez le mode demo python simulator.py -m demo,
qui vous montre un chemin pour la graine 0 (codé en dur).
Parfois, il est impossible pour le robot de rejoindre la cible (regardez par exemple la carte pour la graine 32).
Lisez-le code attentivement. Questions de compréhension:
- Lorsque le monde est généré, comment le nombre d’obstacles est-il choisi ?
- Le tableau
gridest un tableau contenant les nombres0,1ou2. Que signifient ces valeurs? - Comment est trouvée la solution dans le mode
demo?
A*
- À quoi sert la fonction
distance_estimationde A* ? Pourquoi la distance est-elle calculée de cette manière ? - Si le code était complet, si on remplace le contenu de
distance_estimationparreturn 0, quel sera l’effet sur l’algorithme du A* ? (Si vous implémentez le code, n’hésitez pas à essayer!)
Complétez le code de solve qui explore les noeuds.
Complétez le code de build_path qui construit le chemin vers la cible.
Vous pourrez tester votre code avec python simulator.py -m a_star (pensez à tester d’autres graines!)
Value iteration
- Quelle est la fonction de récompense utilisée dans value iteration ?
- Une action
giveup, qui donne systématiquement-100de score est ajoutée aux possibilités, pourquoi ? - Comment choisir cette valeur (ici
-100) pour que l’algorithme fonctionne ?
Faites tourner l’algorithme “à la main” sur un exemple comme celui-ci:

Implémentez le code manquant dans do_iterations.
Implémentez le code manquant dans find_path.
Vous pourrez tester votre code avec python simulator.py -m value.
Bilan
Expliquez la différence principale entre les deux algorithmes utilisés ici. Indiquez d’après vous dans quel cas d’utilisation l’un ou l’autre est meilleur
 Rhoban
Rhoban
 @RhobanRobots
@RhobanRobots